|
1
|
- Building Associations
- Hebb Learning
- Delta Learning
- Making Decisions
- Linear Activation Function
- Nonlinear Activation Functions
- Perceptrons, Pros and Cons
|
|
2
|
- �When two elementary brain-processes have been active together or in
immediate succession, one of them, on reoccurring, tends to propagate
its excitement into the other� (James, 1890)
- �When an axon of cell A is near enough to excite a cell B and repeatedly
or persistently takes place in firing it, some growth process or
metabolic change takes place in one or both cells such that A�s
efficiency, as one of the cells firing B, is increased� (Hebb, 1949)
|
|
3
|
- Modern views of neural association involve the strengthening of synapses
(both excitatory and inhibitory) as well as the weakening of synapses
- These two processes have been combined to create many interesting models
of distributed associative memory
|
|
4
|
- Hebb rule has many problems
- Only learns orthogonal patterns
- Produces error when overtraining
- Unable to deal with linear dependence
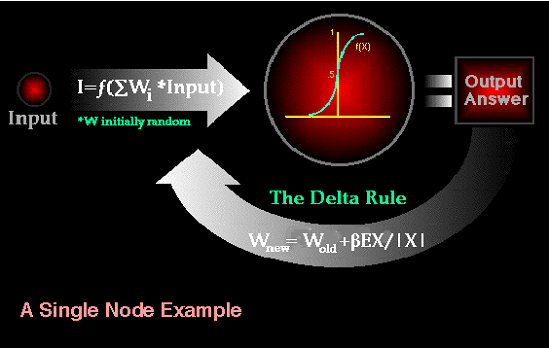
- The delta rule overcomes many of these problems
- Can deal with some correlated patterns
- Only modifies weights when errors exist
- Still cannot deal with linear dependence
|
|
5
|
- One possibility for overcoming these problems would be to build a more
powerful network
- For example, perhaps a chain of distributed associative memories would
serve the purpose
- In this chain, the output of one DAM would be passed along as input to
another, so that layers of connections would be exploited
|
|
6
|
- Linear algebra shows that these sequences can be reduced to a memory
with one layer of connections
- In other words, the sequences don�t add power
- r = W1(W2c) = (W1W2)c
- r = Xc
|
|
7
|
- Why won�t these sequences add power?
- It is because unit activation is a linear function of net input
- For layers to add something that can�t be removed by linear algebra, a
nonlinear transformation of net input must be provided
- In short, we need to use a nonlinear activation function in our
processors
- Fortunately, many are available
|
|
8
|
|
|
9
|
|
|
10
|
|
|
11
|
|
|
12
|
|
|
13
|
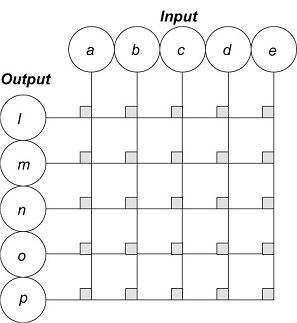
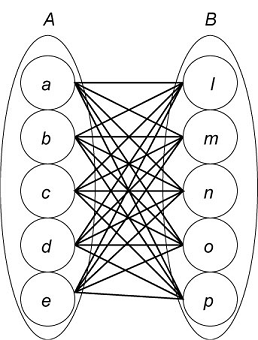
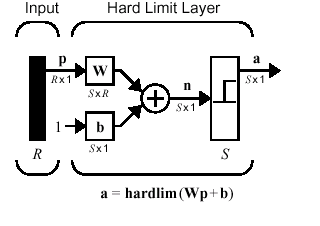
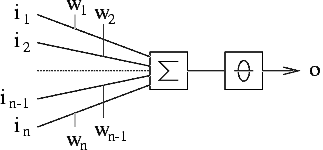
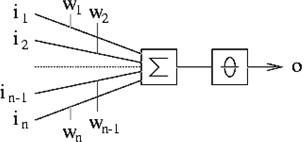
- A perceptron can be viewed as a distributed memory whose output units
use nonlinear activation functions
- It is used to associate an input pattern with a category name
- A perceptron was a trainable pattern classifier!
|
|
14
|
- We would like very much for a perceptron to learn how to categorize
patterns
- This is exactly what Frank Rosenblatt (e.g., 1958) was able to provide:
a learning rule that was guaranteed to train a perceptron to represent
the solution to any problem that a perceptron could solve
|
|
15
|
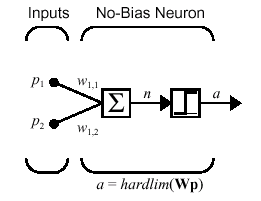
- Assume that the perceptron uses a threshold activation function in its
output.� Rosenblatt used this rule
- Wij(new) = Wij(old) + h(tj � oj)ai
- Compare this learning rule to the delta rule for DAM.� Why does this rule make sense?
- Dt+1 = h ((t - o) � cT)
|
|
16
|
- Assume that the perceptron uses a sigmoid activation function
- Calculus can be used to determine a gradient descent rule that moves the
network downhill in error space as fast as possible
- The calculus is only possible because the sigmoid is a continuous
approximation of the threshold function
|
|
17
|
- Define a �least squares� error term
- E = S(t � o)2
- Use calculus to determine how this error term is changed by a weight
change
- Use this information to define the fastest decrease in error possible
- For f(net) = 1/1+exp(-net):
- Wij(new) = Wij(old) + h(tj � oj)f�(net)ai
- Wij(new) = Wij(old) + h(tj � oj)(ai)(1
- ai)ai
|
|
18
|
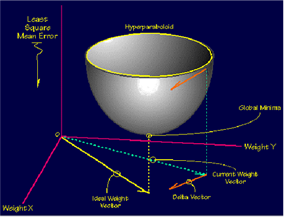
- The gradient descent rule treats error as a surface
- It tries to find the lowest point of this surface
- It uses calculus to find the steepest slope downhill from its current
location on the space
|
|
19
|
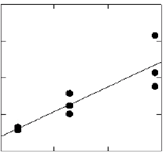
- The perceptron is an improvement over the linear distributed associative
memories that we have already discussed
- It can solve psychologically interesting problems
- It can learn to store associations between linearly dependent vectors
|
|
20
|
- Gallistel has argued that choice behaviour in animals mirrors
reinforcement contingencies
- �Every day two naturalists go out to a pond where some ducks are
overwintering and station themselves about 30 yards apart. Each carries
a sack of bread chunks. Each day a randomly chosen one of the
naturalists throws a chunk every 5 seconds; the other throws every 10
seconds. After a few days experience with this drill, the ducks divide
themselves in proportion to the throwing rates; within 1 minute after
the onset of throwing, there are twice as many ducks in front of the
naturalist that throws at twice the rate of the other. One day, however,
the slower thrower throws chunks twice as big. At first the ducks
distribute themselves two to one in favor of the faster thrower, but
within 5 minutes they are divided fifty-fifty between the two
“foraging patches.” … Ducks and other foraging animals can
represent rates of return, the number of items per unit time multiplied
by the average size of an item� (Gallistel, 1990).
|
|
21
|
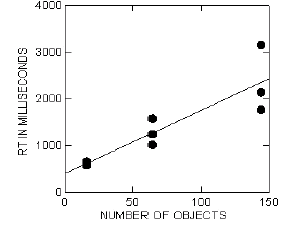
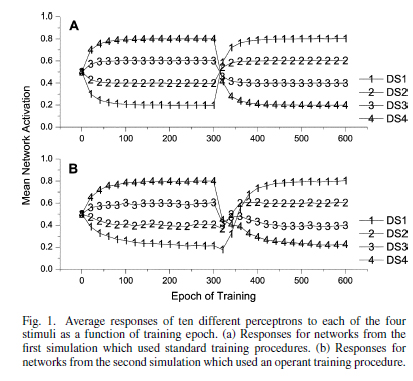
- Perceptron responses are literally a probability judgment about being
reinforced, as shown by Dawson et al. (2009)
- Response shows probability matching
- Probability matching quickly adapts to changing contingencies
|
|
22
|
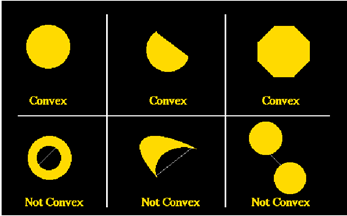
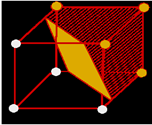
- Draw a figure on the retina
- Choose any two points on the retina (p and r)
- Choose any point q on this line
- For any one of these triplets, if p and r are in the figure, but q is
not, then the figure is not convex
- P ___________Q___________ R
|
|
23
|
|
|
24
|
- jpqr �is a mask; = 1 if p and r are in but q
is out; = 0 otherwise
- Let there be one such mask for every combination of 3 points, and let
each mask have a weight of 1
- Calculate S jpqr
- If S jpqr = 0 the figure is convex
- If S jpqr �1 the figure is not convex
|
|
25
|
- In their book Perceptrons, Minsky and Papert used mathematics to
investigate what perceptrons could and could not learn to do
- They discovered some interesting, and serious, limitations to the
capabilities of perceptrons
- The result was an extreme decline in neural network research
|
|
26
|
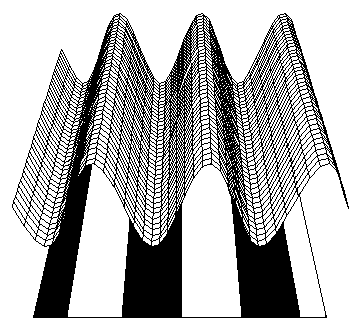
- Networks are frequently used to classify patterns
- They carve a pattern space into decision regions
- Patterns are classified according to these decision regions
|
|
27
|
|
|
28
|
|
|
29
|
- A single, straight cut through the pattern space solves the AND problem
- This means this problem is linearly separable
- The networks of Old Connectionism could learn to solve such problems
|
|
30
|
|
|
31
|
|
|
32
|
- XOR is not a linearly separable problem
- This is because more than 1 cut is required
- As a result, Old Connectionism could not train networks to deal with
this problem
- XOR is a problem for New Connectionism
- Or, a problem for a perceptron with a more sophisticated activation
function!
|
|
33
|
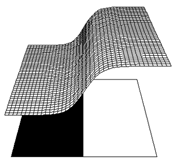
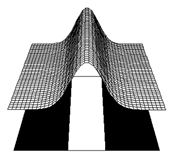
- Named after Ballard (1986)
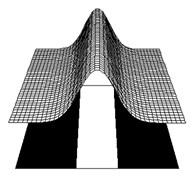
- Gaussian activation function
- G(netpj) = exp[-p(netpj - mj)2]
|
|
34
|
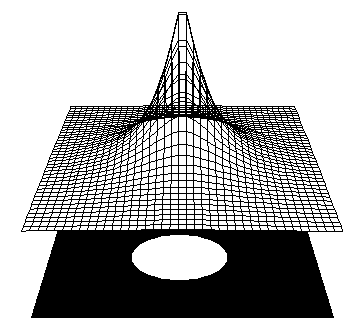
- Standard error term in gradient descent rule
- Dawson & Schoplocher error term
- This second term keeps some of the patterns in the middle of the
distribution!
|
|
35
|
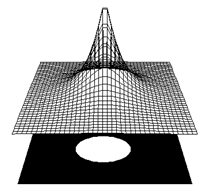
- For G(netpj) = exp[-p(netpj)2]
- Wij(new) = Wij(old) + h(tj � oj)G�(net)ai� + h(tj * net)G�(net)ai
- Using the Gaussian, and the Rumelhart Hinton & Williams chain rule
procedure, one can derive a learning rule for value units:
- Dwij = h(dpi
- epi) apj
- Essentially the same as the gradient descent rule, with the exception of
an elaborated (two component) error term
|
|
36
|
|
|
37
|
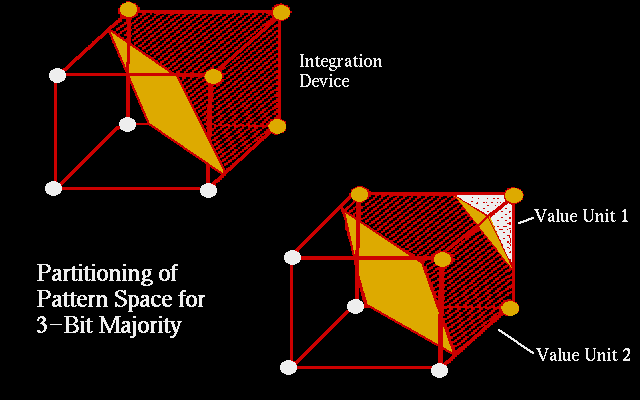
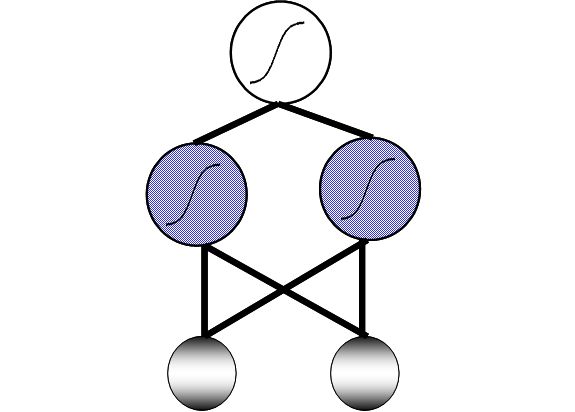
- Let�s use a perceptron program to explore some of the issues raised this
lecture
- Ability to perform beyond DAM
- Ability to deal with most of Boolean logic
- Integration device vs. value unit power in terms of small, linearly
nonseparable problems
- Limitations still exist � we will need to add layers of nonlinear
processors to deal with them � and will talk about how to do this next
week
|

 Notes
Notes{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
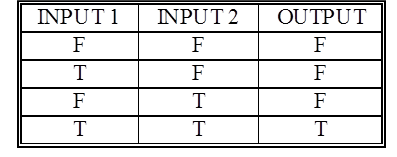{kind=link}
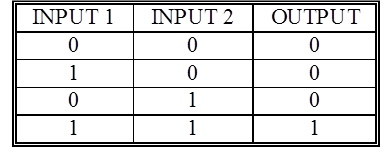{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
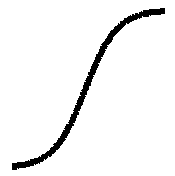{kind=link}
{kind=link}
{kind=link}
{kind=link}
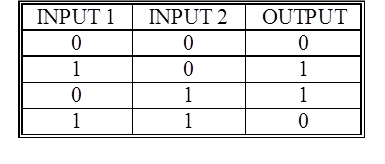{kind=link}
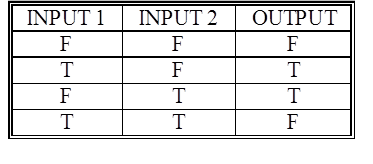{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
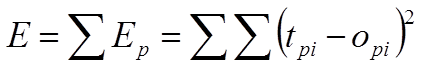{kind=link}
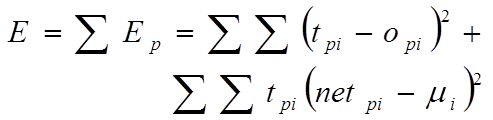{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}